Der genetische Code als Wörterbuch der Translation
Da gezeigt werden konnte, dass Eiweisse die Produkte der Gene sind und dass Gene Abschnitte auf dem DNA-Strang darstellen, suchten die Forscher nach einem Übersetzungscode von der DNS zu den Proteinen.
In der Reihenfolge der Basen ist Information gespeichert
Man vermutete, dass die Reihenfolge (Sequenz) der vier verschiedenen Stickstoffbasen direkt die Reihenfolge der Aminosäuren in den Proteinen definiert. Es musste für die Eiweissbildung ein Übersetzungscode existieren. Weil aber nur vier verschiedene Basen in der DNS vorkommen aber 20 verschiedene Aminosäuren, konnte es nicht sein, dass nur eine Stickstoffbase eine Aminosäure bestimmt (14 = 4). Die Kombination von zwei Nucleotiden könnte nur (24 = ) 16 verschiedene Aminosäuren benennen.
Drei Basen (ein Triplett) bedeuten eine Aminosäure
Deshalb erwartete man, dass der Code aus Kombinationen von drei oder mehr folgenden Nucleotiden besteht. Die Forschung kam auf drei Basen nacheinander, die als Tripletts bekannt wurden. Die Reihenfolge dieser Tripletts auf der DNS (Codons) bestimmt Reihenfolge der Aminosäuren in den Eiweissen.
Der Genetische Code ist das Übersetzungsschema bei der Translation.
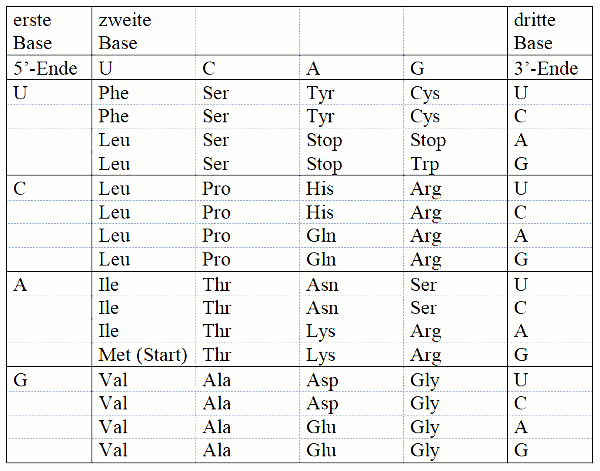
Diesen Code liest man folgendermassen:
U: Uracil
C: Cytosin
A: Adenin
G: Guanin
Dies sind Stickstoffbasen der m-RNA (Messenger-RNA), welcher im Kern abgeschrieben worden ist (Transkription) und dann aus dem Kern wandert.
Eine Aminosäure (hier zum Beispiel Glu = Glutamin) kann also wie folgt durch den genetischen Code bestimmt werden:
Die erste Base muss G sein.
Die zweite Base muss A sein.
Die dritte Base kann A oder G sein.
Das Triplett für Glutamin heisst also entweder GAA oder GAG.
Neben Tripletts, welche Aminosäuren codieren, gibt es auch solche, welche den Anfang oder das Ende eines Proteins codieren:
Start-Triplett: AUG (codiert auch für Methionin)
Stop-Triplett: UAA, UAG, UGA
Weiter zum Zentralen Dogma der Molekulargenetik